The gap we kept hitting
The mnemosyne-engine benchmark proved the math: 74–78% token reduction, 92–98% faster queries, equivalent answer quality. The engine worked. The problem was that proving something works on a benchmark and putting it in a developer's daily workflow are different problems.
A command-line tool is great for a one-off investigation. But most developers who would benefit from smarter code retrieval are already deep in an AI coding environment — Claude Code, Cursor, Zed, Continue, or a terminal session with a local Ollama model. Telling them to jump out of that environment, run a separate CLI, copy results, and paste them back is friction. And friction is where adoption dies.
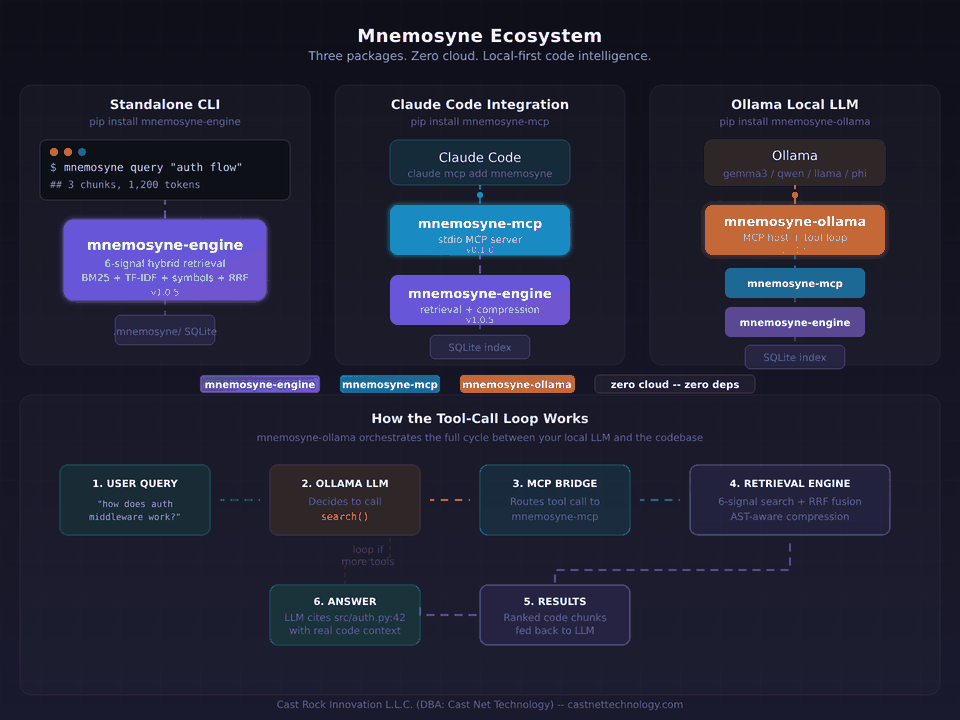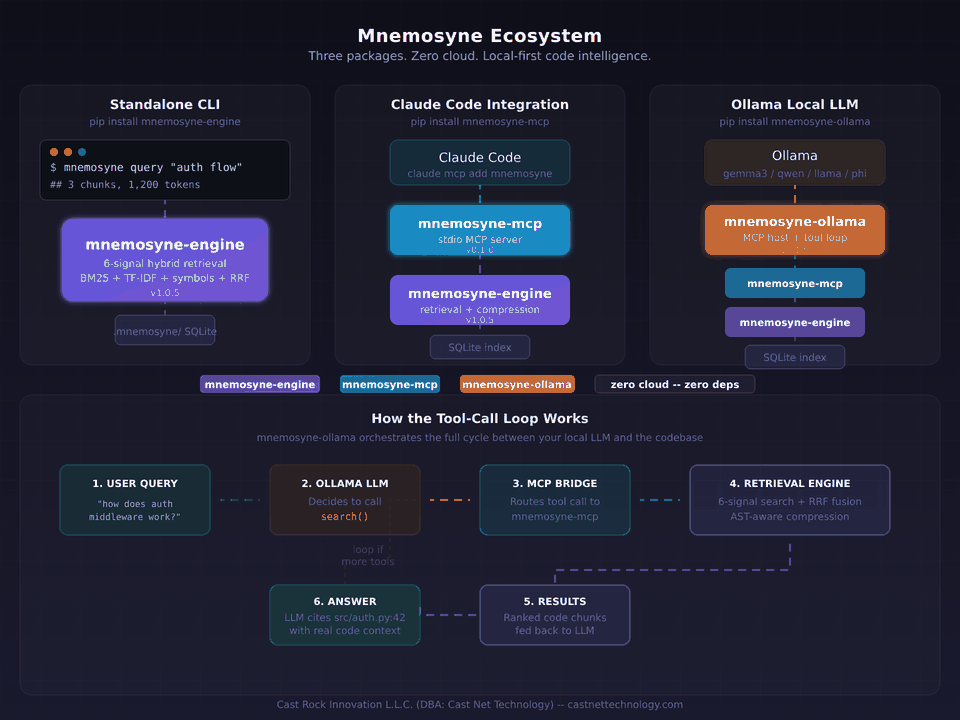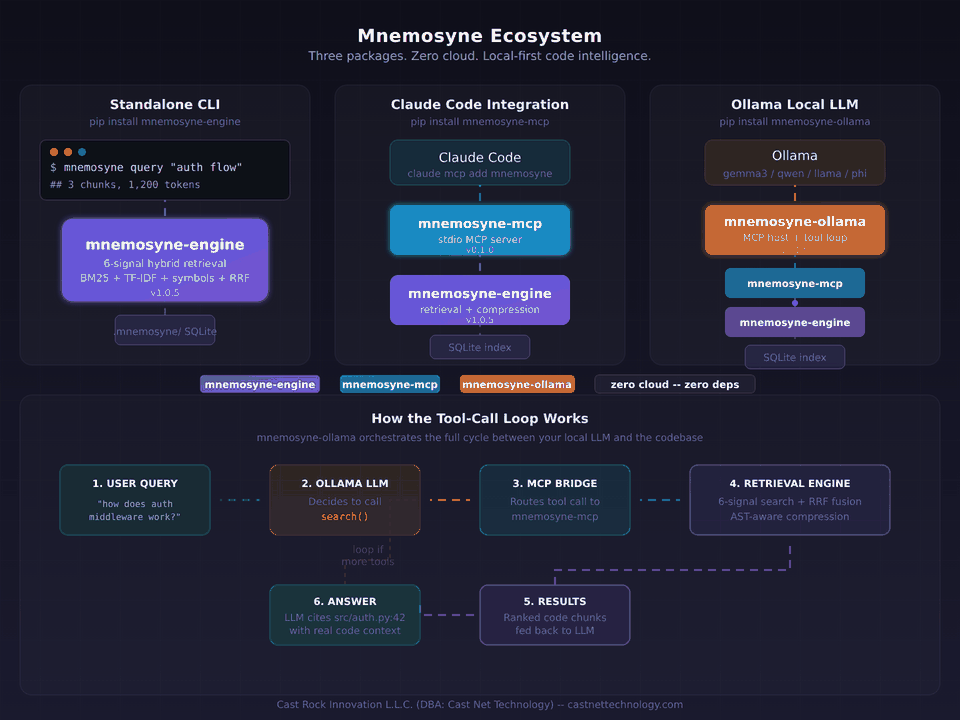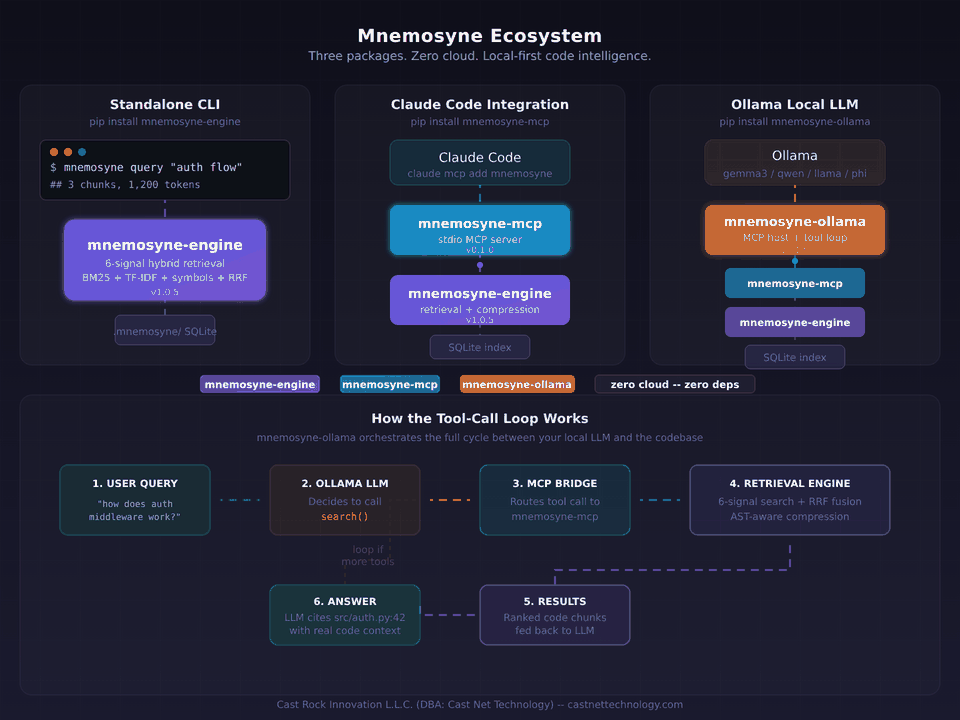
So we built two thin, purpose-built bridges. Neither contains retrieval logic. Both expose the exact same engine to where the work actually happens.
Three packages, one engine
Mnemosyne now ships as a family of PyPI packages. Each solves one problem. Each installs independently. Each layers cleanly on the one below it.
| Package | Role | Install |
|---|---|---|
mnemosyne-engine |
The retrieval engine — indexing, ranking, compression. Zero runtime dependencies. | pip install mnemosyne-engine |
mnemosyne-mcp |
Model Context Protocol server. Plugs the engine into Claude Code, Cursor, and any MCP host. | pip install mnemosyne-mcp |
mnemosyne-ollama |
Lightweight MCP host for Ollama. One command, fully local, zero configuration. | pip install mnemosyne-ollama |
The rule we held ourselves to while building the bridges: neither one can know anything about retrieval. If we had to duplicate any ranking logic, any compression step, any chunking decision, we were doing it wrong. A bridge is a shape adapter, not a second implementation.
Scenario 1: Standalone CLI
This is the engine on its own. You want to investigate a codebase, generate context for a prompt you'll paste into any LLM, or pipe retrieval results into a shell script. Nothing else running, no assistant, no host.
pip install mnemosyne-engine
cd /your/project
mnemosyne init
mnemosyne ingest
mnemosyne query "How does the authentication flow work?"Three commands to install, two commands to prepare, one command per question. The output is ranked chunks with file paths and line numbers, token-budgeted, ready to drop into any context window. This is the surface we benchmarked.
Scenario 2: Claude Code and Cursor via MCP
The Model Context Protocol is the connector standard for AI coding environments. Claude Code, Cursor, Zed, and a growing list of editors and agents speak it natively. An MCP server exposes tools (search, index, inspect) that the host's language model can call when it needs them.
We built mnemosyne-mcp as a thin translator — it listens on stdio, converts MCP tool calls into engine queries, and returns the results in MCP's content format. No re-ranking, no caching layer, no state beyond what the engine already tracks. About 200 lines of bridge code sitting on top of the engine.
# One-time setup in Claude Code
pip install mnemosyne-mcp
claude mcp add mnemosyne mnemosyne-mcp
# Now just ask questions. Claude will call the search tool itself.
> How does the user registration flow connect to the billing provider?The workflow shift is important. You're not running a retrieval tool anymore — the assistant is running it for you, at the moments it decides more context would help. The integration is invisible. The token savings are not.
The same MCP server works with Cursor, Zed, Continue, and any other MCP-compatible host. The protocol is the portability layer.
Scenario 3: Fully local with Ollama
This is the one we had been waiting to build. Ollama runs open-weight models — Llama, Qwen, Gemma, Mistral, Phi, Command-R — on a developer's laptop. It has tool-calling support. It does not have native MCP support.
That's the gap mnemosyne-ollama fills. It's a lightweight MCP host — just the core loop, not a framework. It spawns mnemosyne-mcp as a subprocess, discovers the available tools, translates them into Ollama's tool-calling format, and runs the LLM↔tool loop until the model produces an answer. Everything happens locally. No cloud, no API keys, no telemetry.
pip install mnemosyne-ollama
cd /your/project
mnemosyne-ollama "How does the authentication middleware work?"One command. On a first run it will auto-detect which Ollama model you have, spawn the MCP server, index if needed, search, and return a grounded answer with file citations. No configuration file, no setup wizard, no API key.
And because mnemosyne-ollama holds a conversation, you can follow up:
$ mnemosyne-ollama
mnemosyne-ollama interactive (qwen2.5-coder:14b)
Project: /your/project
Type your question. Ctrl+C to exit.
> what was the last quarterly EBITDA calculation logic?
> which files handle the rate limiting middleware?
> show me the session token rotation flowEvery query runs end-to-end on your machine. If you are working in a regulated environment, behind an airgap, or simply unwilling to ship your code to a third party, this is the one you want.
Why local matters more than ever
We build for regulated industries. Healthcare coding, regulatory intelligence, on-prem document workflows. Our customers have a hard rule: sensitive code and data does not leave their infrastructure. That posture has informed every architectural choice we make.
The same posture is showing up well beyond regulated industries. Developers building proprietary systems, working on acquisitions, handling customer data under NDA, or simply doing early R&D on work they don't want indexed somewhere — all of them ask the same question: can this run without sending anything to a cloud?
For Mnemosyne the answer is now yes, by default, in every delivery vector. The CLI is local. The MCP server is local. The Ollama bridge is local. Cloud is an option, never a requirement.
All three packages are available now on PyPI. Zero runtime dependencies beyond their direct needs, AGPL-3.0 licensed (commercial licenses available).
Get started in one line — pick the scenario that fits how you work:
# Standalone CLI
pip install mnemosyne-engine
# Claude Code / Cursor / any MCP host
pip install mnemosyne-mcp
# Local LLMs via Ollama
pip install mnemosyne-ollamaA few design decisions worth naming
Each package has exactly one dependency chain. mnemosyne-ollama depends on mnemosyne-mcp, which depends on mnemosyne-engine. Installing the top of the stack pulls in exactly what you need. There are no optional extras, no feature flags, no "pro" and "community" split. One install, one thing working.
No new configuration surface. Every bridge inherits its behavior from the engine. Token budgets, ranking signals, compression thresholds — all configurable in one place. The bridges do not introduce their own knobs. Learning the engine is learning the whole stack.
Zero runtime dependencies for the bridges too. mnemosyne-mcp uses only the official MCP Python SDK. mnemosyne-ollama uses only Python's standard library for HTTP and the MCP SDK for server lifecycle. No frameworks, no HTTP clients, no YAML parsers. Small on disk, fast to install, easy to audit.
Same privacy model everywhere. No telemetry, no analytics, no crash reporting. If you want us to know something, you'll tell us.
What comes next
The engine's retrieval quality is the constraint we keep iterating on — there's a known lexical-gap case (queries that reach for concepts not named in the code) where we are still behind where we want to be. The current Phase 3 plan on GitHub tracks that work publicly.
On the delivery side, the next question is whether additional bridges are worth building. We've deliberately avoided a web UI, a REST gateway, a Slack bot, or a cloud-hosted version — those are different products and they belong in different repositories. The three we shipped cover the scenarios we hear about most: investigate with a CLI, work inside an assistant, work offline with a local model.
If there's a fourth scenario we haven't considered, we'd like to hear about it. The bridges are thin enough that adding a new one is mostly about listening.