"The context window is the most expensive resource in any LLM application. Most tools treat it like it's unlimited. We built one that treats every token like it costs money — then made it work everywhere developers actually write code."
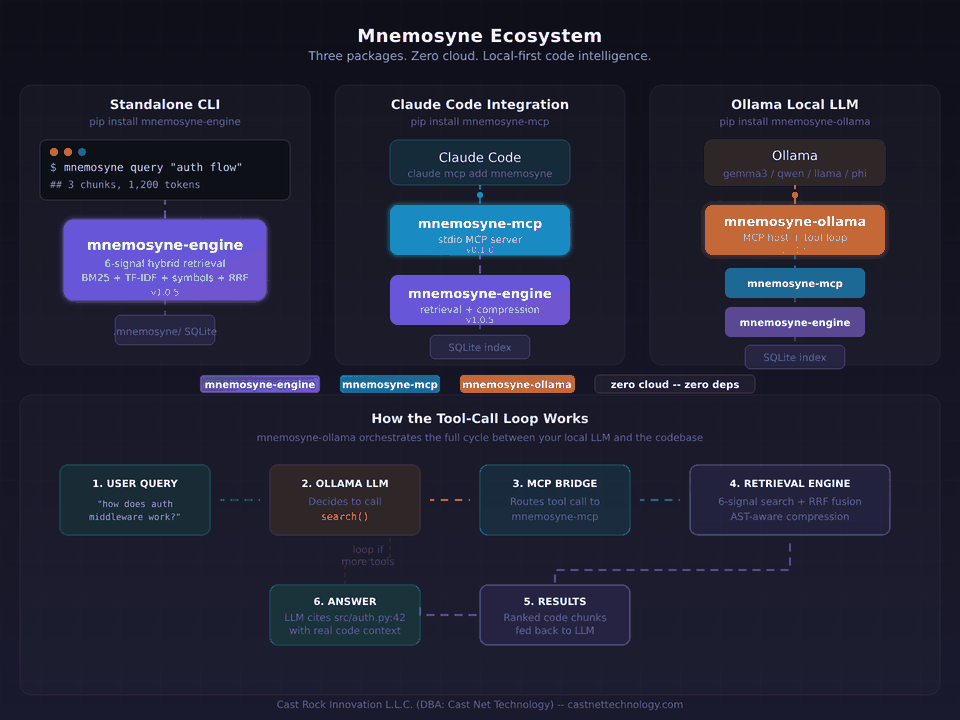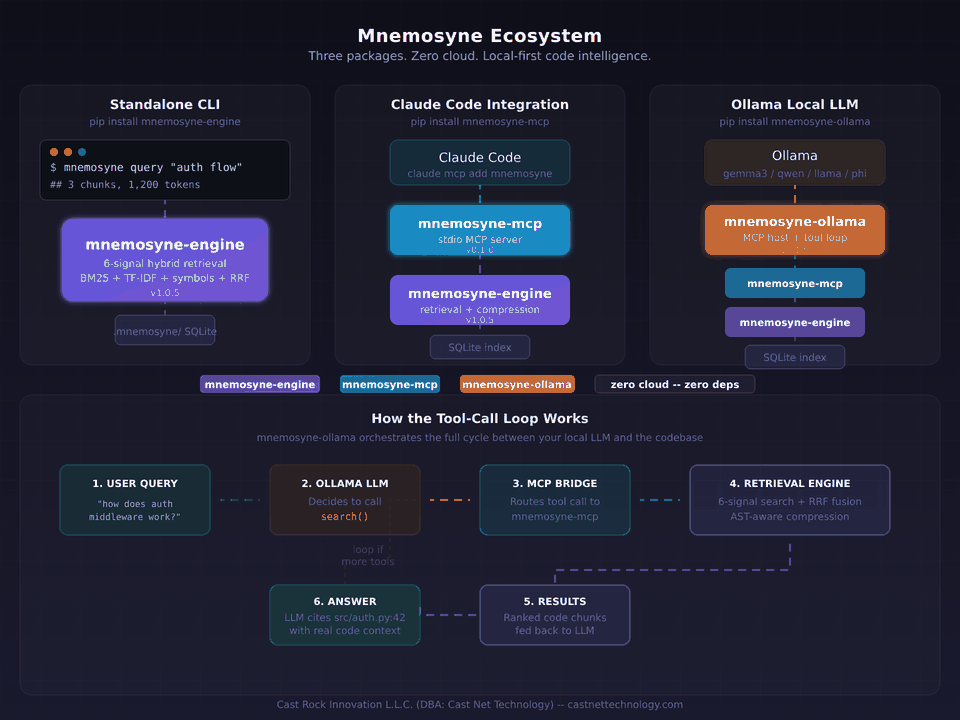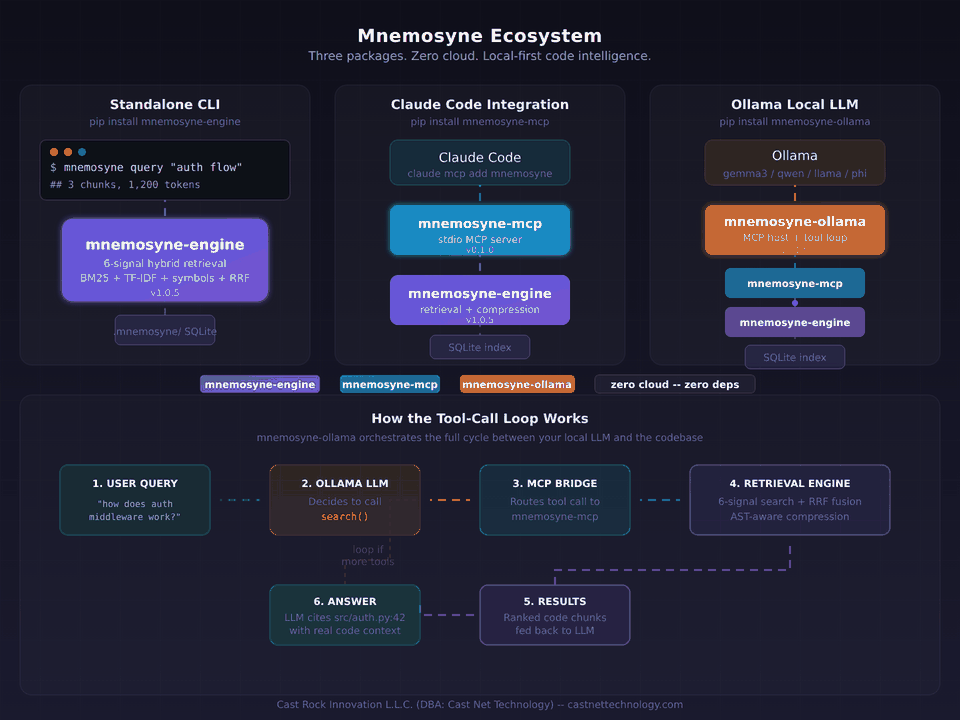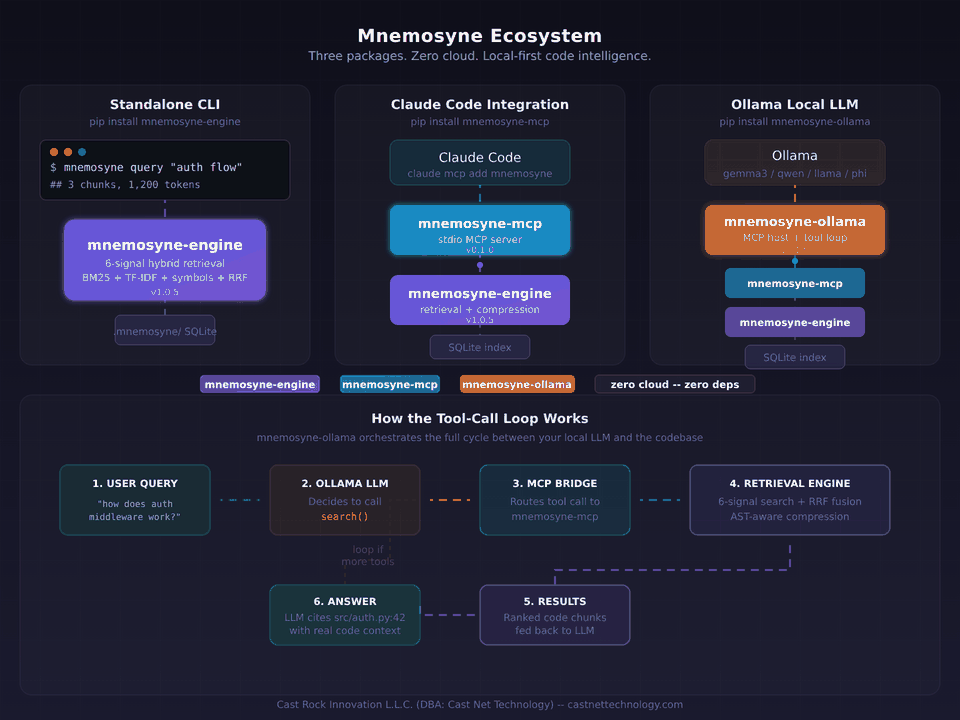
A retrieval engine, an MCP server, and a local LLM bridge. Three packages. One idea.
We were building internal AI agents that read codebases and answered questions about them. The agents worked, but the token bills didn't make sense. We traced it to one problem: context waste. Every time an agent needed to understand a module, it consumed entire files, directory listings, and search results — 40 to 70 percent of the tokens contributed nothing to the answer.
So we built mnemosyne-engine: a retrieval engine that indexes a codebase and returns only the chunks that matter, ranked by value-per-token, within a configurable budget. The engine runs a hybrid pipeline — BM25, TF-IDF, symbol matching, usage frequency, and four additional signals — all fused through Reciprocal Rank Fusion and re-ranked by a cost model that penalizes low-information content. A four-stage compression pipeline strips boilerplate while preserving function signatures, control flow, and documentation. We benchmarked it against a real 844-file production codebase: 74–78% fewer tokens, 92–98% faster queries, equivalent answer quality.
Then we built the hands. mnemosyne-mcp is a Model Context Protocol server that plugs the engine straight into Claude Code, Cursor, Zed, and any other MCP-compatible host. mnemosyne-ollama is a lightweight MCP host that runs the engine fully local against any tool-capable Ollama model — Llama, Qwen, Gemma, Mistral, Phi — with one command and zero configuration. Same engine, three delivery vectors, no cloud required in any of them.
All three are open source under AGPL-3.0 (commercial licenses available), pure Python, zero runtime dependencies beyond their direct protocol needs. 293 tests in the engine alone. Published with OIDC trusted-publisher attestation on PyPI. No telemetry, no analytics, no phone-home. The developers building the next generation of AI tools shouldn't have to solve context waste from scratch — and they shouldn't have to send their code to a third party to get the benefit.

