A public example
Read the code, if you like.
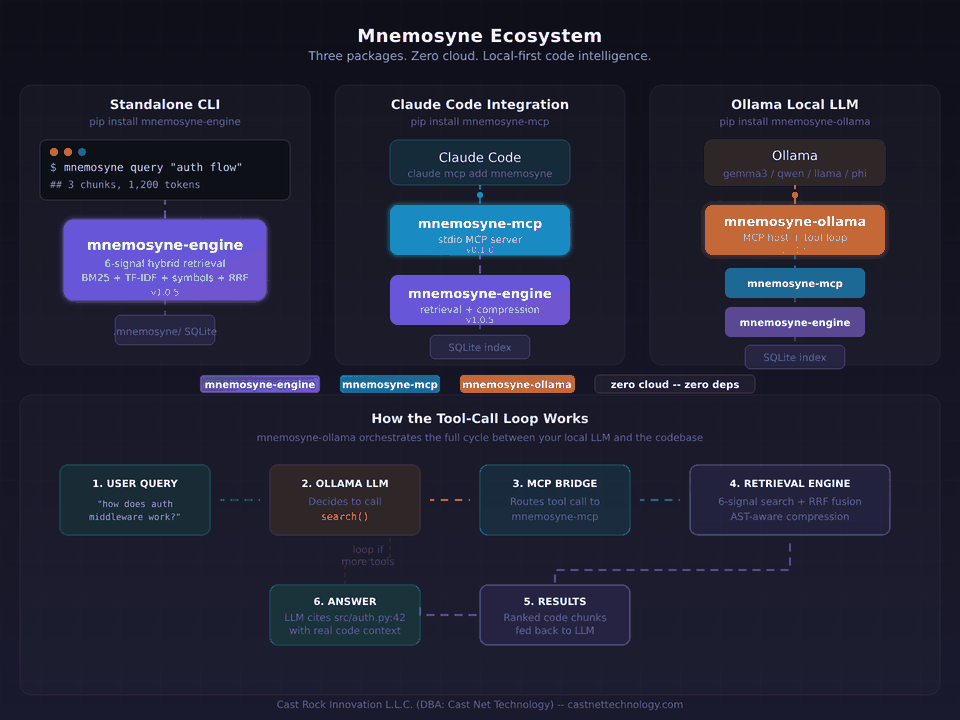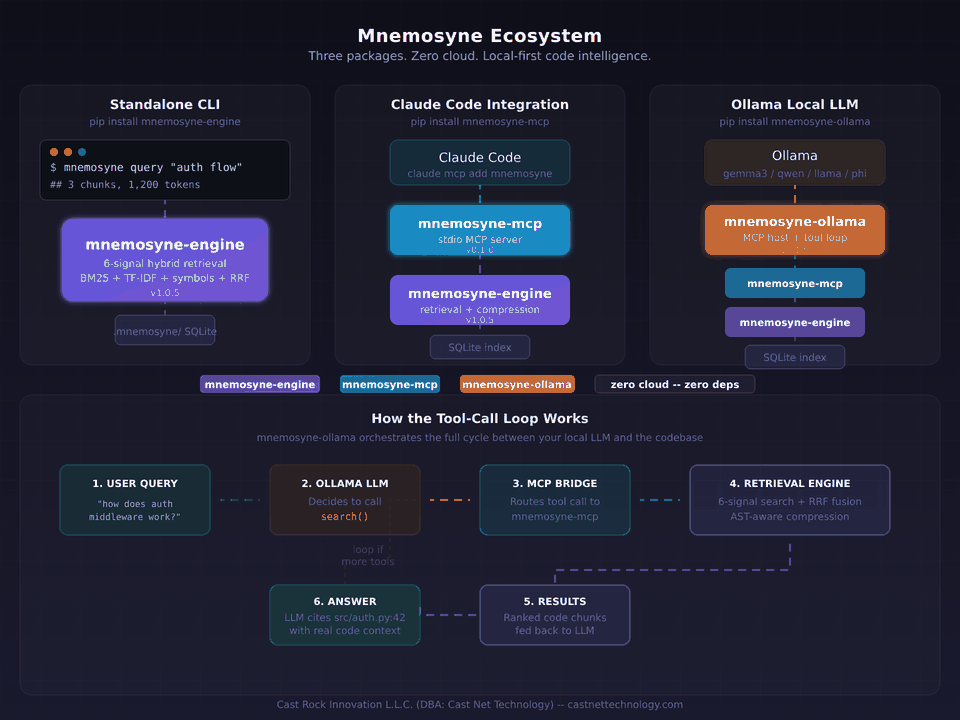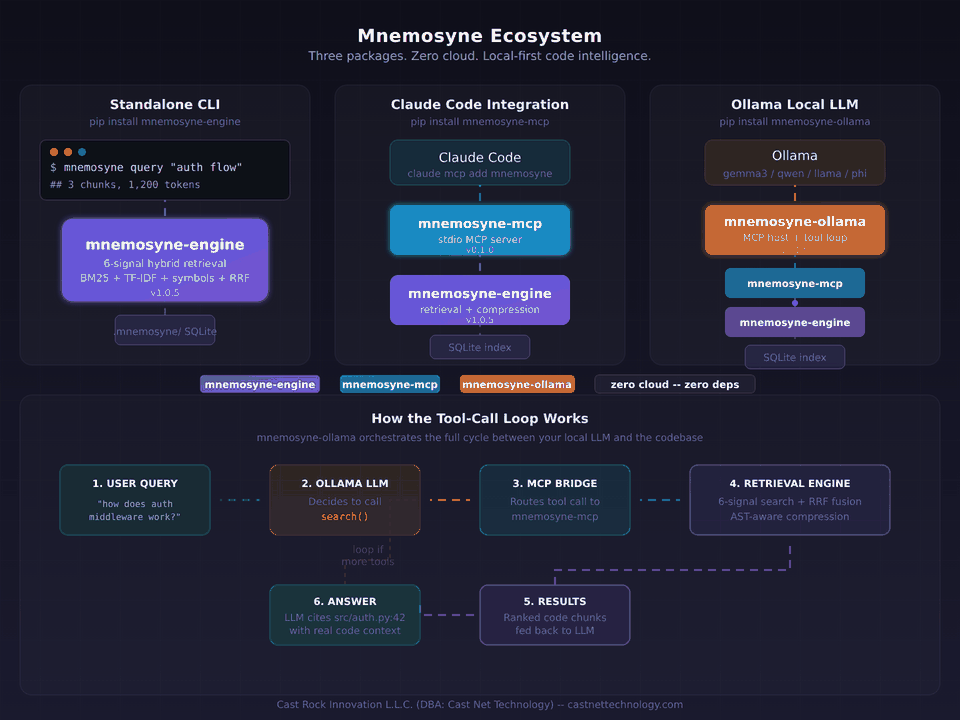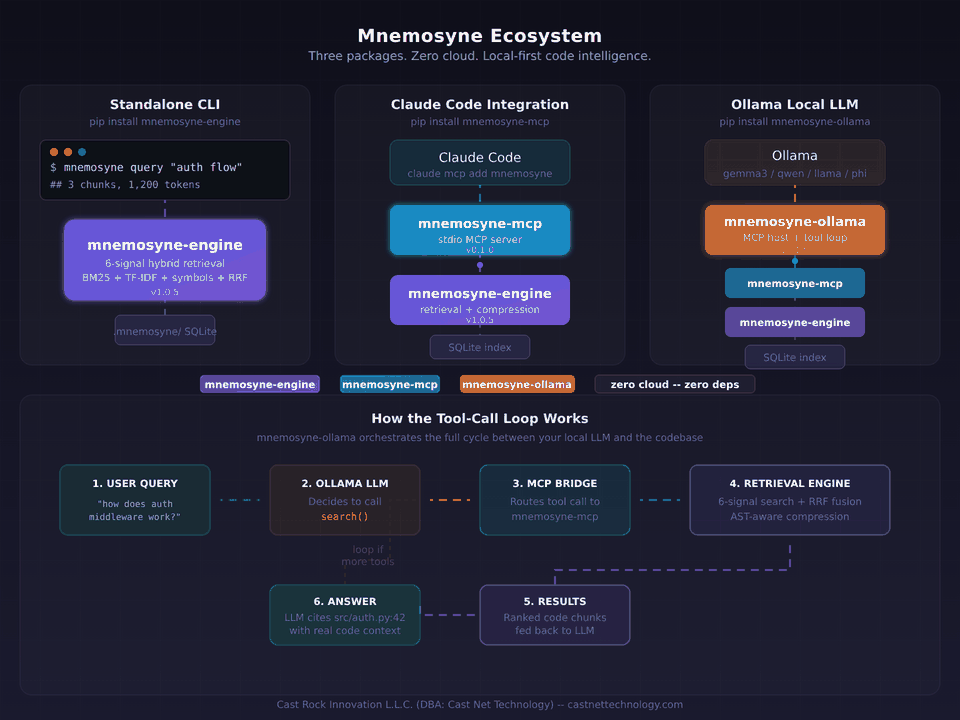
Most of what we build lives quietly inside the teams we built it with — not because we're secretive, just because that's the nature of custom work. One piece of our own internal engineering is out in the open though: Mnemosyne, our LLM context retrieval engine. It's probably the clearest window into how we actually write code — the test suite, the benchmarks, the release attestations, the commit history. No marketing around it. Read it on GitHub if you're curious.
-
mnemosyne-engine — retrieval engine, pure Python, zero runtime dependencies, 293 tests. Cuts typical LLM context waste by 74–78%.
-
mnemosyne-mcp — Model Context Protocol server for Claude Code, Cursor, Zed, and any MCP host.
-
mnemosyne-ollama — lightweight host for local LLMs via Ollama. One command, fully offline.